隨著 AI 日漸盛行,愈來愈多的人都把 AI 當成助理,也希望我們可以直接與 AI 透過語音溝通,而非僅僅只有文字。而我們可以透過 Web Speech API,在瀏覽器做到語音識別,以及幾文字轉成語音的功能,如此就能更有效的與 AI 進行互動。
Web Speech API 分為兩個主要部分:SpeechRecognition 和 SpeechSynthesis,SpeechRecognition 提供語音識別功能,允許應用程式聽取並將使用者的語音轉成文字;SpeechSynthesis 則相反,它提供了將文字轉成語音的功能,可以讓應用程式發聲說話。而我也會依此功能分成兩篇文章,第一篇介紹 SpeechRecognition,第二篇介紹 SpeechSynthesis。
我們先用 SpeechRecognition 來實作一個簡單的語音功能吧!首先,要初始化 SpeechRecognition 物件然後開始識別:
// 建立 SpeechRecognition 物件
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
// 設定語言為中文
recognition.lang = 'zh-TW';
// 開始語音識別
recognition.start();
// 當結果返回時觸發
recognition.onresult = function(event) {
const transcript = event.results[0][0].transcript;
console.log('識別結果:', transcript);
};
瀏覽器會要求使用麥克風的權限,記得按允許唷!
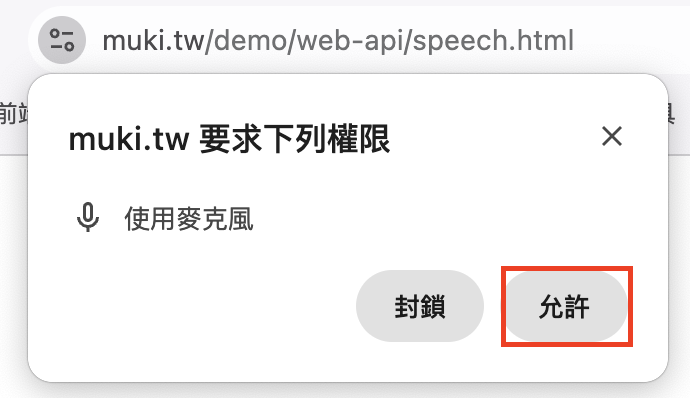
接著我們就可以直接對著螢幕說話了。當語音識別完成後,會通過 onresult 事件返回結果,我們就可以在這裡對識別結果進行各種處理。
如果你有使用上述的程式碼來玩玩看,會發現我們講完一句話後,麥克風就會自動關閉。
如果我們要讓 SpeechRecognition 持續監聽使用者的語音輸入而不會自動關閉,我們可以將 continuous 屬性設為 true。這樣一來,語音識別會在使用者講話過程中持續運行,並且在語音輸入結束後會繼續等待新的語音輸入。
此外也可以將 interimResults 設為 true,他可以即時顯示我們說話中的文字
// 設定為連續模式,讓麥克風不會自動關閉
recognition.continuous = true;
// 即時顯示中間的結果
recognition.interimResults = true;
將程式碼調整一下:
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
// 設定語言為中文
recognition.lang = 'zh-TW';
// 設定為連續模式
recognition.continuous = true;
// 設定為顯示中間結果
recognition.interimResults = true;
// 開始語音識別
recognition.start();
// 當結果返回時觸發
recognition.onresult = function(event) {
let finalTranscript = '';
let interimTranscript = '';
// 解析結果
for (let i = event.resultIndex; i < event.results.length; i++) {
const result = event.results[i];
if (result.isFinal) {
finalTranscript += result[0].transcript;
} else {
interimTranscript += result[0].transcript;
}
}
console.log('即時結果:', interimTranscript);
console.log('最終結果:', finalTranscript);
};
// 當語音識別結束後處理
recognition.onend = function() {
// 重新啟動識別以保持持續監聽
recognition.start();
};
當最終結果有資料時,就表示語音識別結束了,我們會再重新啟動 recognition.start() 以持續監聽
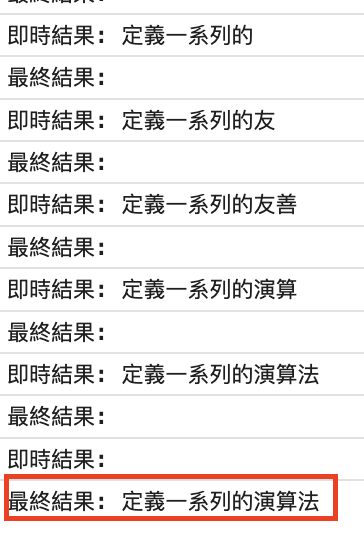
除了 onresult 事件外,SpeechRecognition 還提供了多個事件處理器來管理語音識別過程中的不同狀況。
onspeechstart:使用者開始說話時。onspeechend:使用者停止說話時。onend: 語音識別結束時(前面的範例有用到)。onerror:發生錯誤時。onnomatch:無法匹配語音時。recognition.onspeechstart = function() {
console.log('偵測到語音');
};
recognition.onspeechend = function() {
console.log('語音結束');
};
recognition.onend = function() {
console.log('語音識別結束');
};
recognition.onerror = function(event) {
console.log('發生錯誤:', event.error);
};
recognition.onnomatch = function() {
console.log('無法匹配到語音');
};
這些事件處理器可以幫助我們更好的控制語音識別的過程,並根據不同的狀況進行對應的處理。
例如,可以使用 onerror() 告訴使用者我們無法識別你的語音,並引導使用者重新講一次,避免使用者摸不清狀況。
recognition.onerror = function(event) {
console.error('識別失敗:', event.error);
alert('無法識別你的語音,請再試一次。');
};
可以識別文字後,就能做很多有趣的應用啦!這邊就先很沒創意的跟大家分享,怎麼做到像智慧 TV 那樣,透過說話來搜尋的功能。
在 HTML 的部分,做了一個簡單的說明與顯示語音狀態。然後我會設定,當使用者說出開始搜尋這四個字時,就會停止語音辨識,並連到 Google 搜尋:
<p>請直接說出你要搜尋的關鍵字,當你說出「開始搜尋」時,就會停止語音辨識,並開始搜尋。</p>
<p id="status">狀態: 等待語音輸入</p>
<p id="search-term">語音內容: <span id="term"></span></p>
JavaScript 有在幾個重要的地方做了註解:
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
let searchTerm = '';
recognition.lang = 'zh-TW';
recognition.continuous = true;
recognition.interimResults = true;
recognition.onresult = function(event) {
let interimTranscript = '';
let finalTranscript = '';
for (let i = event.resultIndex; i < event.results.length; i++) {
const result = event.results[i];
if (result.isFinal) {
finalTranscript += result[0].transcript;
} else {
interimTranscript += result[0].transcript;
}
}
// 更新顯示的即時結果和最終結果
document.getElementById('term').textContent = finalTranscript + interimTranscript;
// 檢查是否包含「開始搜尋」關鍵字
if (finalTranscript.includes('開始搜尋')) {
// 去除「開始搜尋」並取得剩餘文字作為搜尋關鍵字
searchTerm = finalTranscript.replace('開始搜尋', '').trim();
// 停止語音識別
recognition.stop();
// 更新狀態
document.getElementById('status').textContent = '狀態: 開始搜尋中...';
// 執行搜尋操作
performSearch(searchTerm);
searchTerm = '';
} else {
// 更新搜尋關鍵字
searchTerm = finalTranscript + interimTranscript;
}
};
recognition.onstart = function() {
document.getElementById('status').textContent = '狀態: 語音識別中...';
};
recognition.onend = function() {
document.getElementById('status').textContent = '狀態: 語音識別結束';
};
recognition.onerror = function(event) {
console.error('語音識別錯誤:', event.error);
document.getElementById('status').textContent = '狀態: 語音識別錯誤';
};
// 開始語音識別
recognition.start();
// 執行搜尋操作
function performSearch(query) {
if (query) {
console.log('搜尋關鍵字:', query);
const searchUrl = 'https://www.google.com/custom?q=' + encodeURIComponent(query);
window.location.href = searchUrl;
} else {
console.log('沒有提供搜尋關鍵字');
}
}
一樣錄了一個小動畫給大家看效果:
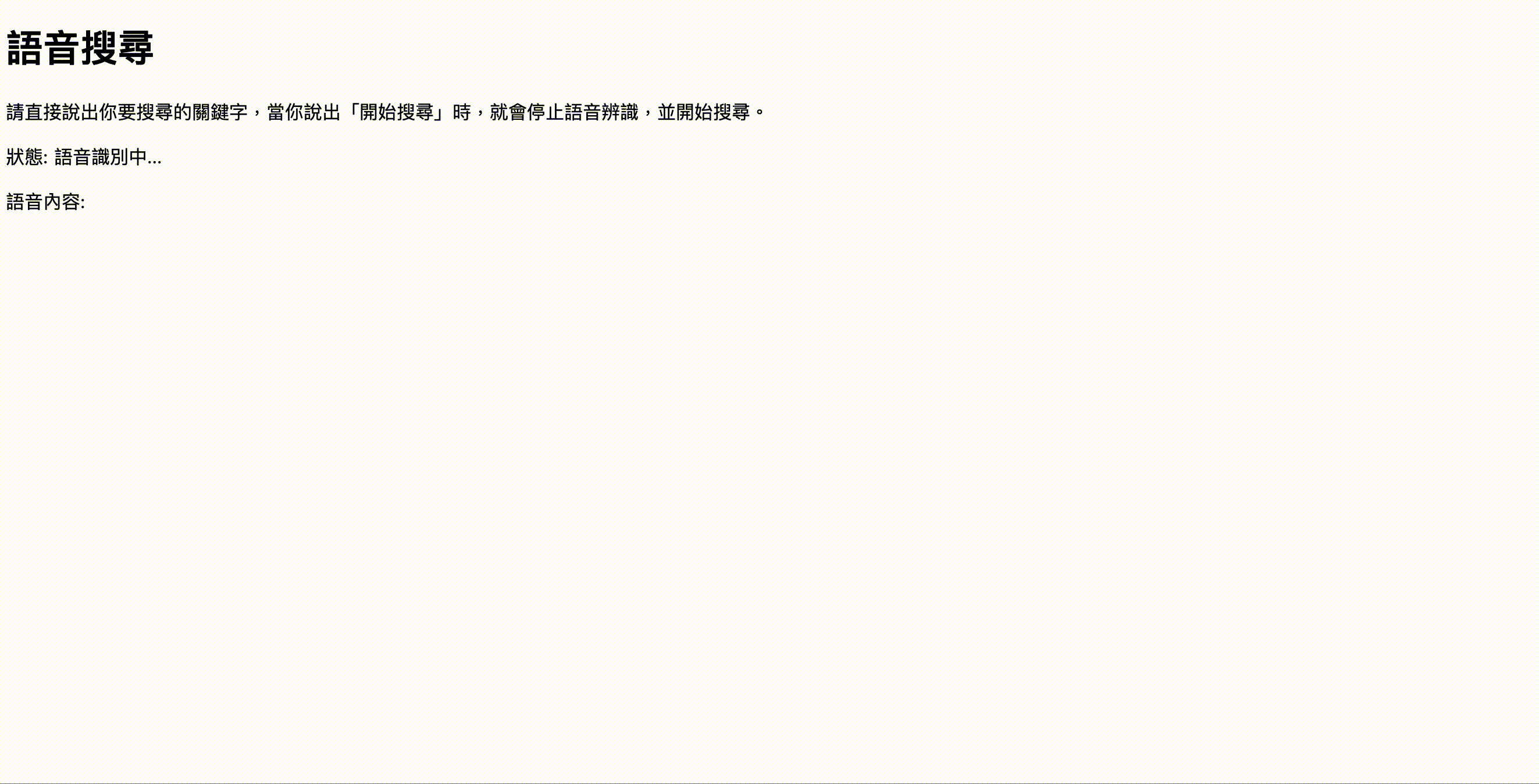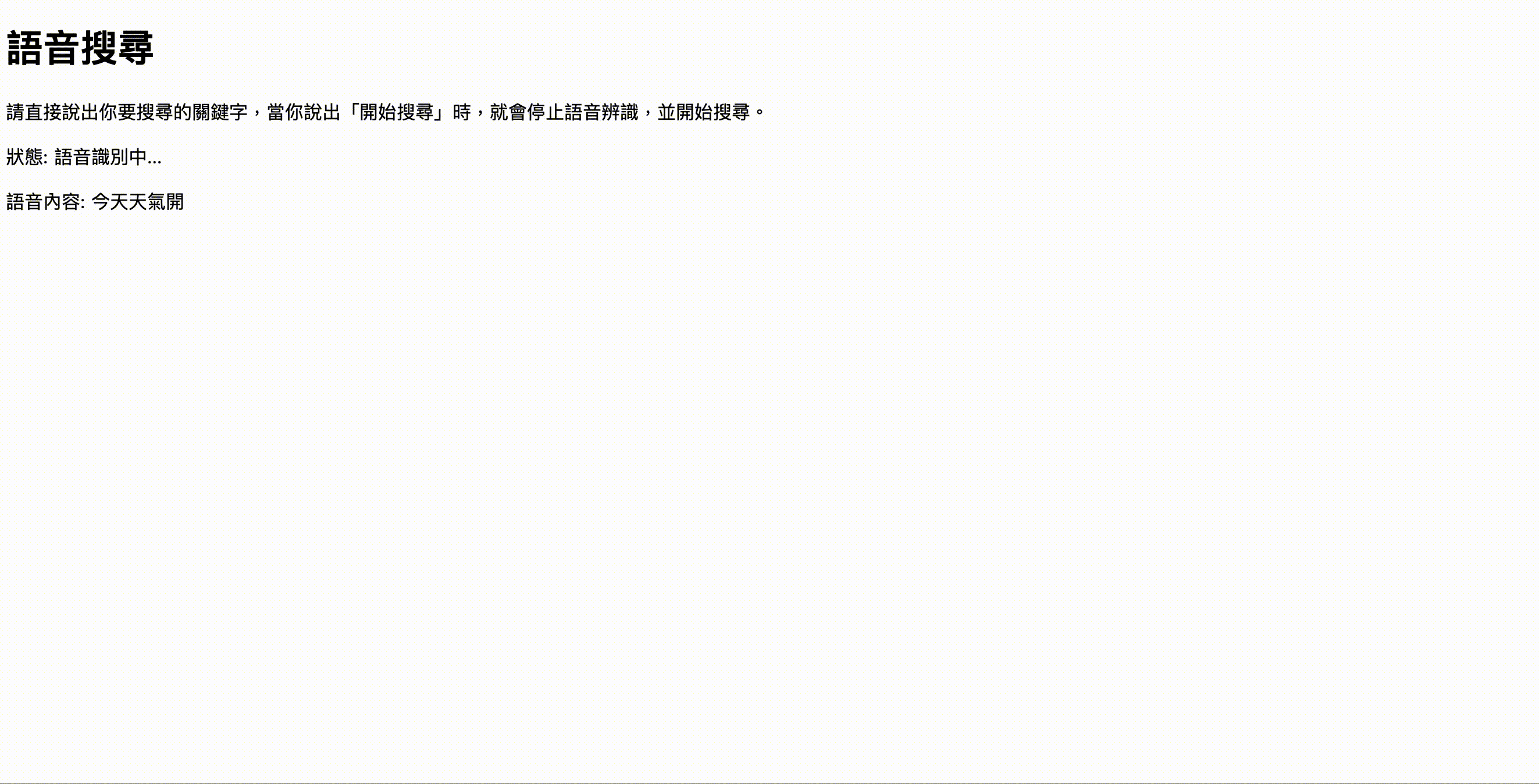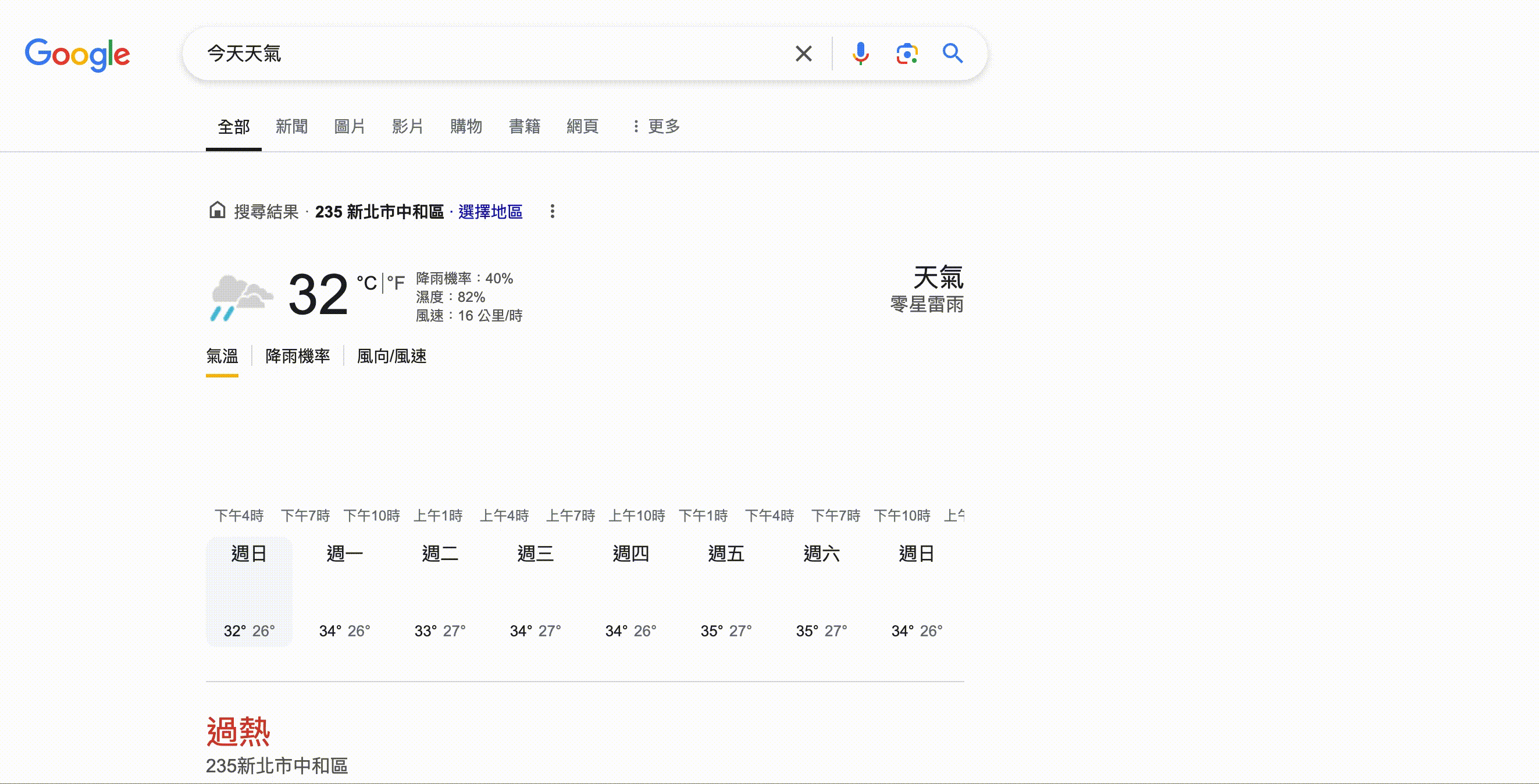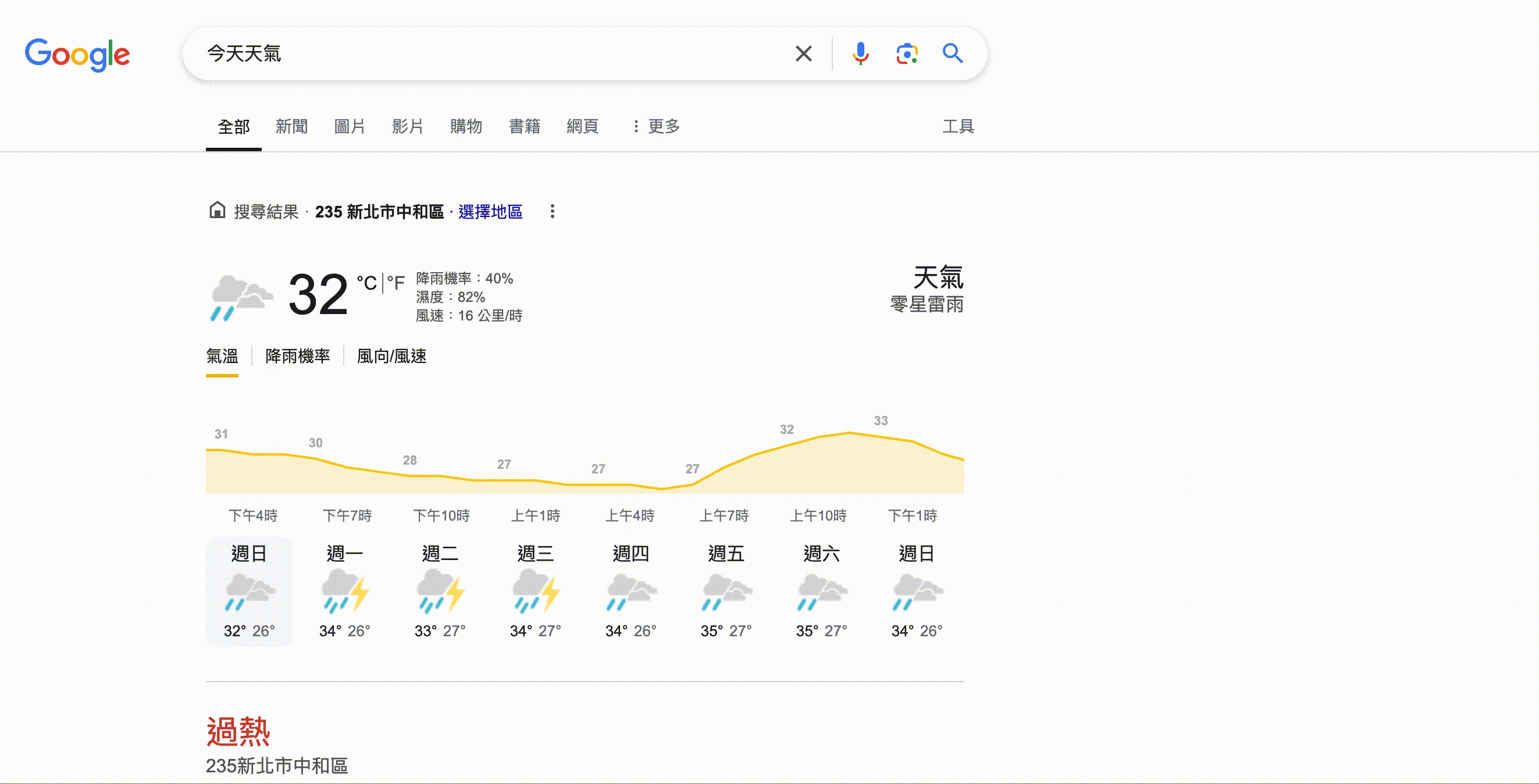
範例程式碼網址:https://mukiwu.github.io/web-api-demo/speech.html
SpeechRecognition 可以結合很多好玩的東西做出豐富的應用情境,不管是從語音輸入,到現在的 AI 助理,我相信他的潛力是無窮的,大家現在開始學起來,保證入股不虧!
以上,有任何問題,都歡迎留言討論唷。


 iThome鐵人賽
iThome鐵人賽